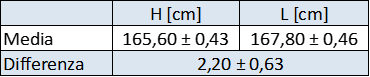Si propone un percorso sperimentale che porta a riconoscere gli errori come parte integrante del processo di misura di qualunque grandezza fisica. Si propone di misurare l'altezza di una persona e di stabilire se la sua altezza è maggiore quando è sdraiata oppure quando è in piedi. In effetti da sdraiati siamo leggermente più alti (circa 2 cm) rispetto a quando siamo in piedi, ma l'altezza di una persona è una grandezza che si misura con una certa difficoltà. Quindi se l'errore di misura non è trattato in modo corretto possiamo non riconoscere la differenza reale.
Scheda sintetica delle attività
Proponiamo la misura una grandezza comune: l'altezza di una persona, semplice da realizzare ma intrinsecamente poco precisa. L'importanza di una valutazione corretta dell'errore di misura diventa evidente quando si cerca di stabilire quanto sia affidabile la differenza osservata tra l'altezza di una persona in piedi o da sdraiata.
Si misura l'altezza di uno studente in piedi come media di N misure e si riconosce alla media un'affidabilità maggiore della singola misura.
Si discute di definizione di errore di misura motivando l'uso della deviazione standard.
Si scopre perché la media di N misure è più affidabile di una misura singola e come valutare l'errore sulla media.
Si scopre come confrontare quantitativamente due misure e quale significato dare al risultato ottenuto.
I fogli elettronici allegati possono essere usati per semplificare le procedure di calcolo. Inoltre contengono simulazioni di dati con distribuzioni Gaussiane che possono essere usate per mostrare in modo empirico gli effetti della propagazione degli errori su grandezze derivate.
Risorse necessarie
Fogli di carta e scotch di carta;
squadrette, quaderni, libri;
metri diversi (da ferramenta, da sarto, fettuccia, da mobili, etc...);
foglio elettronico.
Prerequisiti necessari
Saper calcolare la media e la deviazione standard;
conoscere il significato di deviazione standard e di errore sulla media;
sapere usare un foglio elettronico;
Obiettivi di apprendimento
Si riconosce l'errore come insito nel processo di misura;
si affronta in modo critico il problema di definire l'errore di misura;
Si impara a:
quantificare l'affidabilità di un dato sperimentale;
utilizzare la deviazione standard per il calcolo degli errori;
trattare in modo quantitativo gli errori ci misura;
confrontare i risultati di misure diverse;
usare un foglio elettronico per semplici calcoli statistici (media, dev.st, errore della media).
Dotazioni di sicurezza
Nessuna
Svolgimento
Introduzione
Si propone un percorso sperimentale che porta a riconoscere gli errori come parte integrante del processo di misura di qualunque grandezza fisica. L'errore di misura stabilisce l'affidabilità di una dato sperimentale ed è essenziale per confrontare dati, verificare ipotesi e modelli. Per questo è importante che sia valutato in modo corretto e quantitativo usando regole condivise.
Proponiamo la misura una grandezza comune: l'altezza di una persona, semplice da realizzare ma intrinsecamente poco precisa, e cerchiamo di stabilire se la persona è più alta da sdraiata. La differenza c'è (circa 2 cm) ma modesta, se confrontata con la precisione della singola misura. Per stabilire se gli effetti osservati sono significativi bisogna imparare a trattare in modo corretto gli errori di misura.
I fogli elettronici allegati possono essere usati per semplificare l'analisi dei dati e facilmente modificati e adattati anche ad altri esempi analoghi.
L'ipotesi
E' ragionevole pensare che l'altezza (o la lunghezza!) di una persona, intesa come distanza dalla pianta dei piedi alla sommità del capo, sia maggiore da sdraiato che in piedi? In effetti sì: da sdraiati si distende la colonna vertebrale e si rilassano le articolazioni, quindi è lecito aspettarsi un allungamento.
Proviamo a verificare sperimentalmente l'ipotesi : vedremo che per quantificare l'effetto è indispensabile valutare correttamente l'errore di misura.
La misura e l'incertezza
Si sceglie un volontario da misurare es. Alessia (nome a caso) e si chiede a Barbara (nome a caso) di misurare l'altezza di Alessia in piedi, segnando sul muro (meglio usare un foglio di carta attaccato con scotch di carta) il riferimento della sommità del capo e misurando poi la distanza suolo. Levarsi le scarpe non è essenziale: dal momento che si vuole stabilire una differenza tra in piedi e sdraiato, è facile convincersi che avere o no le scarpe è ininfluente. Si mettono a disposizione strumenti diversi tra i quali scegliere: squadre (o oggetti squadrati come libri e quaderni), metri diversi (fettuccia, metro da sarto, metri di carta, metro da falegname, etc...) e lasciamo che Barbara scelga a piacere gli strumenti che ritiene più idonei. In questa fase è bene lasciare agli sperimentatori la scelta degli strumenti e di come usarli: in alcuni casi assisteremo ad errori anche grossolani nelle operazioni di misura (disallineamento degli strumenti, letture sbagliate, etc...) ma siccome lo scopo è proprio trattare gli errori di misura tutto fa gioco.
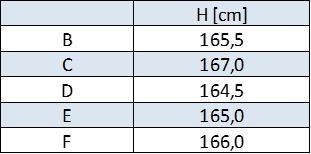
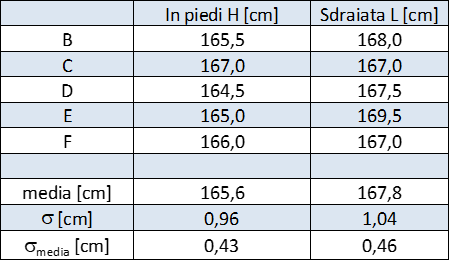
La misura ottenuta da Barbare è: $ H = 165,5\ [cm]$.
Si chiede ad altri studenti (es.: Claudia, Daniele, Elena, Francesco) di ripetere la misura e registriamo i valori. Raccogliere almeno 5-6 misure, eventualmente chiedere anche due misure allo stesso operatore. Per evitare confronti (e quindi aumentare la dispersione dei risultati) ad ogni misura sostituiamo o spostiamo il foglio su cui viene preso il riferimento.
Si ottengono i valori riportati in tabella 1.
Tabella 1: altezza di Alessia in piedi misurata da 5 studenti
Si possono osservare differenze di 2-3 cm o più tra i valori riportati.
Di solito i risultati sono riportati con la precisione di 1 cm più raramente alcuni dichiarano una precisione di mezzo centimetro. Intuitivamente chi misura si rende conto che indicare una precisione maggiore non ha molto senso. Potrebbe essere una discussione da riprendere più avanti.
Domande: perché i valori dell'altezza di Alessia sono tutti diversi? A cosa sono dovute le differenze? La discussione deve far riconoscere come i valori diversi siano un effetto intrinseco nel processo di misura: in parte dovute al misurando, in parte allo strumento, in parte all'abilità dello sperimentatore. Un elenco delle possibili sorgenti di errore aiuta a capire l'origine delle differenze osservate e a riconoscere che effetti analoghi esistono sempre, ogni qual volta si effettui la misura di una grandezza fisica. In questo caso possiamo riconoscere:
la diversa manualità dell'osservatore
differenze nella posizione di Alessia (se chiediamo a Barbara di effettuare una nuova misura, probabilmente non sarà uguale alla prima)
differenza nell'allineamento della squadra,
la sommità del capo non è ben definita
il metro che misura la distanza dal pavimento al "segno" non è perfettamente verticale,
...
Dovendo dare un valore all'altezza di Alessia in piedi è intuitivo scegliere la Media (Il calcolo si può fare usando la funzione MEDIA() di un foglio elettronico come EXCEL-Microsoft o CALC-OpenOffice): $$ \bar{x} = \frac{1}{N} \sum_{i=1}^N x_i\ \ \ \ \ \ [1]$$
Quindi, dovendo dare un valore all'altezza di Alessia in piedi scriveremmo: $\bar{H} = 165,6\ [cm]$. Però la media non è il valore vero dell'altezza di Alessia! Per convincersene basta ripetere le misure: avremo quasi certamente un valore medio diverso.
Domanda: Ma se tutti i valori sono diversi come stabilire il valore vero? Purtroppo il valore vero non è accessibile, il meglio che si può fare è stabilire un intervallo entro il quale è ragionevole aspettarsi di trovare il valore vero o almeno il risultato di ulteriori misure. Per far questo dobbiamo associare alla misura una quantità che rappresenta una stima di quanto stiamo sbagliando: l'errore di misura.
Le norme internazionali (ISO: International Organization for Standardization) prescrivono che: nel riportare la misura di una grandezza fisica è obbligatorio riportare l'errore di misura, esso ci fornisce indicazioni riguardo alla qualità della misura. Senza queste informazioni i risultati di una misura non possono essere né confrontati tra loro né confrontati con riferimenti o standard [pdf, online]. Quindi l'errore di misura quantifica la qualità di un dato ed è un'indicazione essenziale ogni qual volta si riporta il valore di una grandezza misurata perché stabilisce l'affidabilità del dato: minore è l'errore più la misura è precisa e quindi affidabile.
Un modo comodo e veloce per stabilire l'errore di misura potrebbe essere usare la semi-dispersione $\epsilon$: $$\epsilon = \frac{x_{max}-x_{min}}{2}\ \ \ \ \ \ [2]$$
dove $x_{max}\ e\ x_{min}$ sono rispettivamente i valori massimo e minimo osservati. La semidispersione dei dati della tabella 1 vale 1,3 [cm]. Usando ε come errore di misura potremmo scrivere: $\bar{H} = 165,6\ \pm 1,3\ [cm]$. Anche se la semi-dispersione semplifica i calcoli, ci dobbiamo convincere che questa non è una valutazione corretta della qualità del nostro dato e quindi e dobbiamo trovare un parametro diverso.
Ci arriviamo per gradi ponendoci alcune domande.
Domande:
La semi-dispersione è l'errore massimo? Ovvero: siamo certi che il valore vero dell'altezza di Alessia sia tra 164,3 e 166,9 [cm]? Ovviamente no, non possiamo essere sicuri che una misura successiva dia un valore entro la semidispersione. Inoltre spesso gli estremi non sono equidistanti dalla media.
Se ora rimisurassimo l'altezza di Alessia ci possiamo aspettare un valore certamente entro 164,3 e 166,9 [cm]? Sicuramente no, esistono distribuzioni, prima tra tutte la Gaussiana, che hanno gli estremi a infinito, in questi casi la semi-dispersione è, a priori, infinita.
Possiamo aspettarci un valore probabilmente entro 164,3 e 166,9? Si ma che significa probabilmente? Siamo in grado di valutare la probabilità di osservare un valore entro 164,3 [cm] e 166,9 [cm]? E' maggiore del 50%, maggiore del 70%? ...
Queste osservazioni ci dovrebbero lasciare una sensazione di incertezza e la voglia di saperne di più.
Intanto vediamo se è ragionevole usare la semi-dispersione (2) per il calcolo dell'errore. Forse no: i valori estremi di una distribuzione (massimo e minimo) sono quasi certamente quelli affetti dall'errore maggiore (minore accuratezza dell'operatore, distrazione, strumento sbagliato, etc...) quindi affidandosi ai dati più sbagliati porta quasi certamente a sovrastimare dell'errore. Si può sottolineare il fatto che una stima prudente dell'errore ha maggiori probabilità di racchiudere il valore vero. Tuttavia l'eccesso di prudenza può portare a mascherare differenze significative, proprio quelle che permettono di distinguere tra un modello e un altro, verificare o falsificare una teoria. Ad esempio, se sovrastimo l'intervallo di valori normali per delle analisi cliniche, rischio di non riconoscere il segnale di una patologia! Nel nostro caso, usare la semidispersione porterebbe a non riconoscere come vere le differenze reali.
La semi-dispersione non consente di quantificare il rischio di sbagliare cioè non è possibile stabilire la probabilità che il valore vero sia nell'intervallo definito dalla ε né la probabilità che una nuova misura ricada in quell'intervallo. In effetti le norme internazionali [GUM-ISO] definiscono l'errore di misura come la deviazione standard della distribuzione dei possibili risultati della misura (vedi esperimento 5-Fisica e introduzione alla guida GUM) dove la deviazione standard è definita come: $$\sigma = \sqrt{\frac{1}{N-1} \sum_{i=1}^N\left(x_i-\bar{x}\right)^2}\ \ \ \ \ \ [3]$$
E' sicuramente una formula più complicata della [2] (per questo la semi-dispersione è comoda!) ma implementata nei comuni fogli elettronici (EXCEL (MS) o Calc (Oo) ) con la funzione DEV.ST( ).
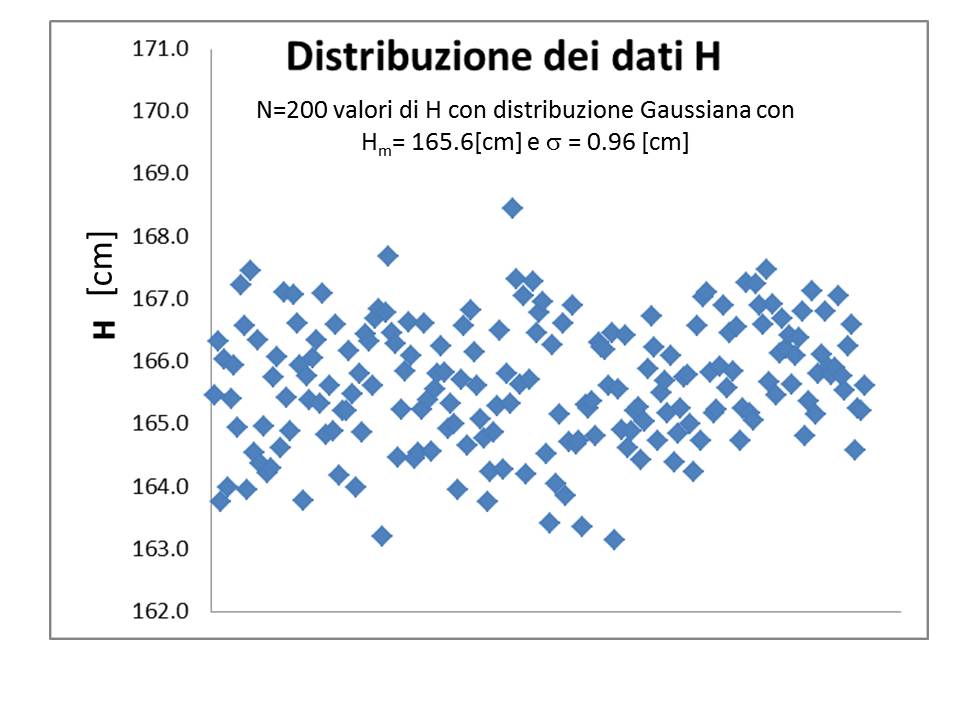
Per mettere in evidenza la differenza tra dispersione e deviazione standard in figura 1 sono mostrati 200 valori di H ottenuti utilizzando il simulatore di numeri casuali di Excel, assumendo una distribuzione Gaussiana con valore medio Hm e deviazione standard σ prese dai dati di tabella 1: rigenerando la sequenza (tasto F9) per uno stesso valore di σ si possono osservare valori estremi anche molto distanti con dispersione anche oltre 6 cm. Questi dati estremi determinerebbero l'errore, diverso per ogni sequenza. La deviazione standard resta invece invariata.
I pregi della deviazione standard rispetto alla semi-dispersione sono diversi:
La deviazione standard usa tutti dati di un set di misura, non solo gli estremi. E' facile convincersi che in questo modo l'effetto di un singolo errore risulta attenuato.
Il teorema (o diseguaglianza) di Cebyšëv stabilisce che, per qualunque distribuzione di risultati, la probabilità che il valore osservato differisca dal valore vero per più di $n \cdot \sigma$ è sempre minore di $\large{\frac{1}{n^2}}$:
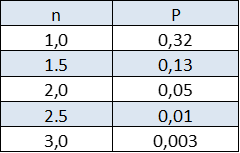
Questo permette di quantificare il rischio che la misura sia affetta da un errore maggiore di n volte σ. In pratica è possibile fare previsioni e calcolare (stimare) il rischio di sbagliare. Per n=1 il risultato è scontato (la probabilità e' sempre minore di 1) ma la probabilità che il valore vero disti dalla misura più di 2σ è minore del 25%, la probabilità di fare un errore maggiore di 3σ è inferiore al 10%. In effetti la diseguaglianza di Cebyšëv è un criterio molto prudente, nel caso di una distribuzione Gaussiana la probabilità di commettere un errore maggiore di una deviazione standard è circa il 30%, maggiore di 2σ è circa 5%, più di 3σ è circa 0.3% (Tabella 2).
Tabella 2: probabilità (P) di compiere un errore maggiore di $n \cdot \sigma$ per una distribuzione gaussiana
Il punto 2 è importante: stabilisce che l'uso della deviazione standard consente di valutare il rischio che il valore misurato differisca dal valore vero per più n volte σ. In effetti lo scopo dell'analisi statistica è proprio trasformare l'incertezza (Ho ottenuto H, ma quanto è alta veramente Alessia?) in una valutazione quantitativa del rischio che ci si assume fornendo un risultato (Ho ottenuto H, la probabilità di aver sbagliato l'altezza di Alessia più di Δ è minore del y%). Questo è un aspetto importante che ci aiuta a capire a cosa serve effettivamente l'errore di misura e perché è fondamentale averne una definizione condivisa e quantitativa.
L'errore di misura è definito tramite la σ e la grandezza misurata si indica con x ± σ. L'intervallo x ± σ non assicura di racchiudere tutti i possibili valori di una futura misura però possiamo dare una stima della probabilità che l'intervallo contenga il valore vero. Qui può essere utile aprire una breve parentesi per discutere di dati reali, risultati e previsioni prendendo spunto dai giornali o dati riportati sul WEB. Ad esempio: sondaggi elettorali, previsioni del tempo, indagini sociali, previsioni di borsa, e perché no, anche di voti a scuola.
Figura 1: simulazione di misure di H (N=200) ottenute usando una distribuzione gaussiana con valore atteso $\bar{H} =165,6\ [cm]\ e \sigma =0,96\ [cm]$. Usando il foglio Excel in allegato si possono generare nuove sequenze usando il tasto F9.
A questo punto:
Domanda: Quale è l'altezza di Alessia in piedi? La deviazione standard dei dati in tabella 1 è σ=0, 96 [cm], quindi la risposta quasi scontata è: $$ \bar{H} = 165,60 \pm 0,096\ [cm]$$ La risposta non è corretta e vediamo perché.
L'errore della media
Si chiede ad Alessia di farsi misurare da sdraiata: usando un paio di banchi o la cattedra (... anche sul pavimento), con le piante dei piedi poggiate al muro, si prende il riferimento della sommità del capo di Alessia e si misura la distanza del riferimento dal muro.
Barbara misura (indichiamo con L le misure da sdraiata) ottenendo il valore $L_B = 168 [cm]$.
In questo caso Alessia sembra più alta da sdraiata che in piedi, il che sembra confermare l'ipotesi. Ma è facile convincerci che non possiamo escludere che la differenza sia dovuta al caso. Non è raro che l'altezza misurata da sdraiati sia minore almeno di una dei valori ottenuti in piedi, in questo caso potremmo essere ancora più indecisi riguardo alle conclusioni da trarre (figura 1).
Ci si rende conto di come l'aleatorietà del processo di misura non ci permetta di decidere con sicurezza se il nuovo risultato sia significativo o meno.
Domanda: come fare per stabilire se Alessia da sdraiata è più alta che in piedi? Idea: se $L_B$ differisce da $\bar{H}$ più dell'errore di misura allora è plausibile che Alessia sia più lunga da sdraiata!
Domanda: quale è l'errore su $L_B$? Per l'errore su $\bar{H}$ abbiamo usato la deviazione standard dei dati (4), ma LB è una misura singola! Nelle discussioni in aula una proposta frequente è quella di usare l'errore di lettura, però questo è molto piccolo (dell'ordine del mm) mentre abbiamo visto che i risultati possono differire anche di alcuni cm (è facile verificarlo prendendo una seconda misura di Alessia sdraiata: la differenza tra le due misure sarà probabilmente dell'ordine del cm). Inoltre, usando l'errore di lettura la misura singola avrebbe un errore molto minore della media, il che non è sensato.
In mancanza di altre informazioni, per stabilire l'errore su LB dobbiamo usare le informazioni della misura precedente. Abbiamo visto che le misure dell'altezza di Alessia in tabella 1, presentano una dispersione dovuta a diverse sorgenti di errore (la manualità dell'osservatore, differenze nella posizione di Alessia, differenze nell'allineamento della squadra, la sommità del capo non ben definita, il metro non perpendicolare al pavimento (muro), etc.... Tutti questi fattori aleatori fanno si che le misure si disperdano in un certo intervallo con deviazione standard circa 1 cm (σ=0.96 [cm]). Non avendo altre informazioni è lecito aspettarsi una dispersione analoga per le misure da sdraiata (questo è errore di tipo B, vedi discussione nell'esperimento 5-Fisica e guida GUM) e scrivere: $$L_B = 168,0 \pm 0,96$$
Notare l'incongruenza: l'errore su $\bar{H}$ ricavato alla fine del capitolo precedente e l'errore su $L_B$ definito ora sono uguali! Ma la media di 5 misure è sicuramente (o almeno intuitivamente) più affidabile di una misura singola, quindi l'errore su $\bar{H}$ deve essere minore dell'errore su $L_B$.
Si può verificare sperimentalmente (oppure usiamo i dati nel file excel allegato) che continuando a prendere misure dell'altezza di Alessia, il valore della media cambia poco (dopo 10-15 misure l'effetto è molto piccolo) e cosi la deviazione standard della distribuzione. Allora perché assegniamo una maggiore fiducia al valore medio piuttosto che al valore singolo?
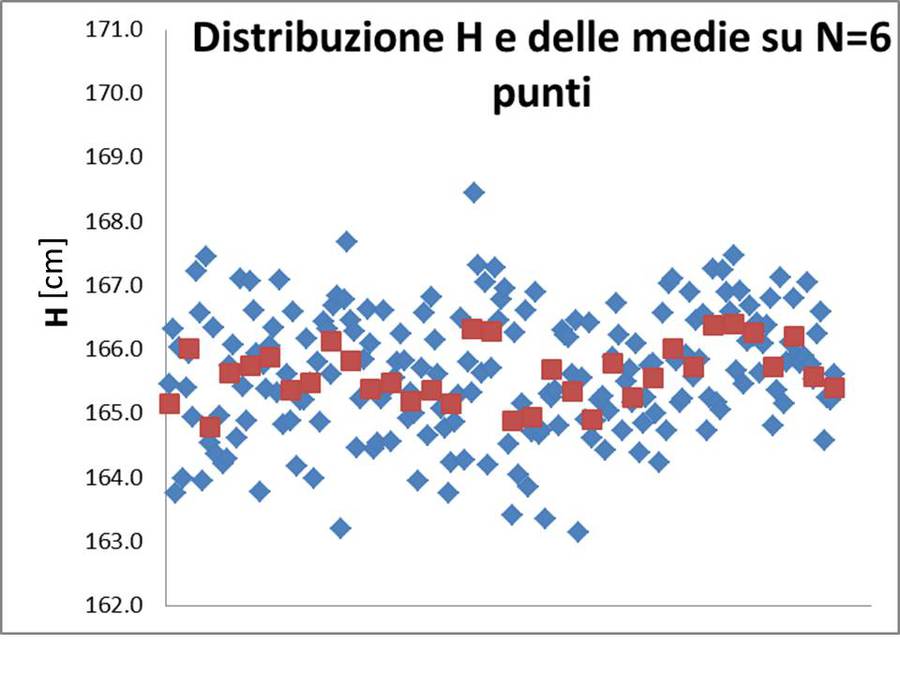
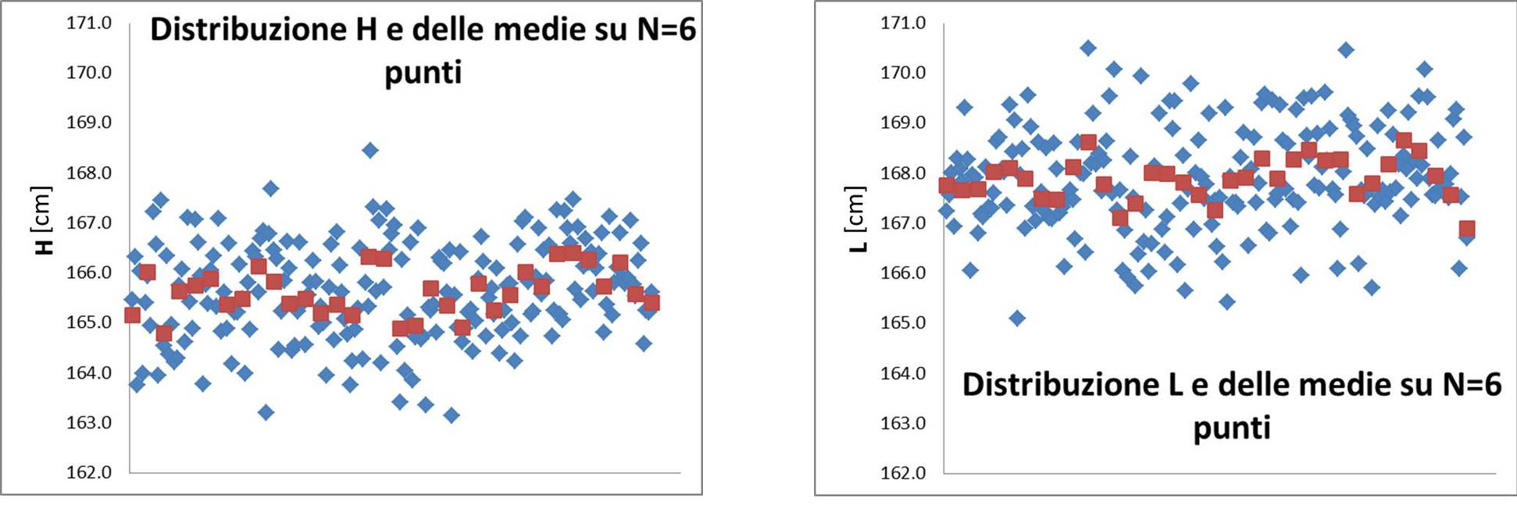
Figura 2: Simulazione di 200 misure di H (in blu) confrontati con le medie ottenute prendendo 6 misure per volta (in rosso). La distribuzione delle medie è chiaramente più stretta della distribuzione dei singoli valori. Il confronto fa capire perché abbiamo intuitivamente più confidenza nei valori medi piuttosto che nei valori singoli e verifica empiricamente il teorema del limite centrale.
La risposta è in uno degli enunciati del teorema del limite centrale, fondamentale per la statistica e l'analisi dei dati sperimentali: i valori medi ottenuti effettuando N misure della stessa grandezza hanno una distribuzione (approssimativamente) Gaussiana con deviazione standard: $$\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{N}}\ \ \ \ \ \ [4]$$ dove σ è la deviazione standard della distribuzione dei dati. L'enunciato del teorema è più chiaro osservando i dati di figura 2: qui i singoli dati (gli stessi di figura 1) sono presi a gruppi di 6 e mediati, i valori medi sono mostrati in rosso: è evidente che i valori medi si distribuiscono più vicini al centro della distribuzione e questo ci spiega perché abbiamo istintivamente più confidenza nel risultato di una media piuttosto che di una misura singola. Il teorema del limite centrale stabilisce di quanto si riduce la dispersione delle medie rispetto alla dispersione dei dati singoli.
Quindi, l'errore corretto da assegnare alla misura dell'altezza di Alessia ottenuta effettuando N (N=5 in questo caso) misure è [vedi Wiki1, Wiki2]: $$\sigma_{\bar{H}} = \frac{\sigma}{\sqrt{N}} = 0,43\ [cm]$$
Nota: la [4] suggerisce che sia in teoria possibile raggiungere una precisione infinita ripetendo le misure un numero infinito di volte. E' utile discutere fino a quale precisione abbia senso spingersi e quale sia l'impegno richiesto: in questo caso spingersi ad una precisione maggiore di 0.5 cm è probabilmente poco sensato ma notiamo che, per arrivare ad un'errore sulla media dell'ordine del mm sarebbero necessarie circa 100 misure!
Alessia è più lunga da sdraiata?
Per comodità conviene prendere lo stesso numero di misure di Alessia da sdraiata e confrontare i valori medi $\bar{H}\ e \bar{L}$ (tabella 3). Tabella 3: valori delle misure di altezza H e di lunghezza L
Per stabilire se effettivamente Alessia è più lunga da sdraiata ($\bar{L}>\bar{H}$) è necessario confrontare le due misure e stabilire quanto sia affidabile la differenza osservata. La trattazione rigorosa del problema richiede l'uso di test statistici (test di reiezione delle ipotesi) ed è sicuramente complicata per uno studente di liceo. Però possiamo ragionare intuitivamente: se la differenza tra $\bar{L}\ e \bar{H}$ è grande rispetto agli errori, allora posso dire con una certa sicurezza che Alessia da sdraiata si allunga e l'ipotesi iniziale è corretta.
La differenza è: $D=\bar{L}-\bar{H} = 2,2\ [cm] $ . Sia $\bar{L}$ che $\bar{H}$ sono valori affetti da un errore di misura: si può dimostrare che se una grandezza è la somma o differenza di due grandezze aleatorie indipendenti, l'errore è la somma in quadratura degli errori sulle singole grandezze (vedi Nota 1). Quindi essendo $D=\bar{L}-\bar{H} $ l'errore su D è: $$\sigma_D = \sqrt{\sigma_{\bar{H}}^2 + \sigma_{\bar{L}}^2} = 0,63\ [cm]\ \ \ \ \ \ \ [5]$$ quindi: $D = 2,20 \pm 0,63\ [cm]$; tabella 4 riporta la sintesi dei risultati ottenuti:
Tabella 4: sintesi dei risultati ottenuti
Domande:
Quale fiducia possiamo avere nel risultato?
E' plausibile che Alessia è alta uguale in piedi e sdraiata?
Quanto è probabile che l'effetto osservato sia dovuto al caso?
Cos'è $\sigma_D$?
L'ultima domanda è la più importante: secondo la definizione di errore di misura (paragrafo 2) $\sigma_D$ rappresenta la stima della deviazione standard della distribuzione dei possibili risultati che si otterrebbero ripetendo le misure di Alessia in piedi e sdraiata. Quindi per rispondere alle altre domande ragioniamo cosi: se non ci fosse differenza tra l'altezza di Alessia in piedi e da sdraiata avremmo fatto un errore di misura Δ=3.5 $\sigma_D$ usando la diseguaglianza di Cebyšëv possiamo dire che la probabilità di fare un errore cosi grande è minore del 10% (1/3.52 = 0.08), la probabilità che l'effetto osservato sia vero è alta (migliore del 90%). In effetti la diseguaglianza di Cebyšëv è un criterio molto prudente, sappiamo dal teorema del limite centrale che le medie hanno una distribuzione (in buona approssimazione) Gaussiana e, per una distribuzione Gaussiana, un errore maggiore di 3 $\sigma_D$ è molto raro (minore di 0.1%, Tabella 2) quindi possiamo essere praticamente certi che da sdraiata Alessia è più alta che da in piedi (Nota 3).
Nota: l'errore massimo (semi-dispersione) non avrebbe permesso di riconoscere una differenza tra l'altezza di Alessia in piedi e da sdraiata: vedi figure 3 e 4.
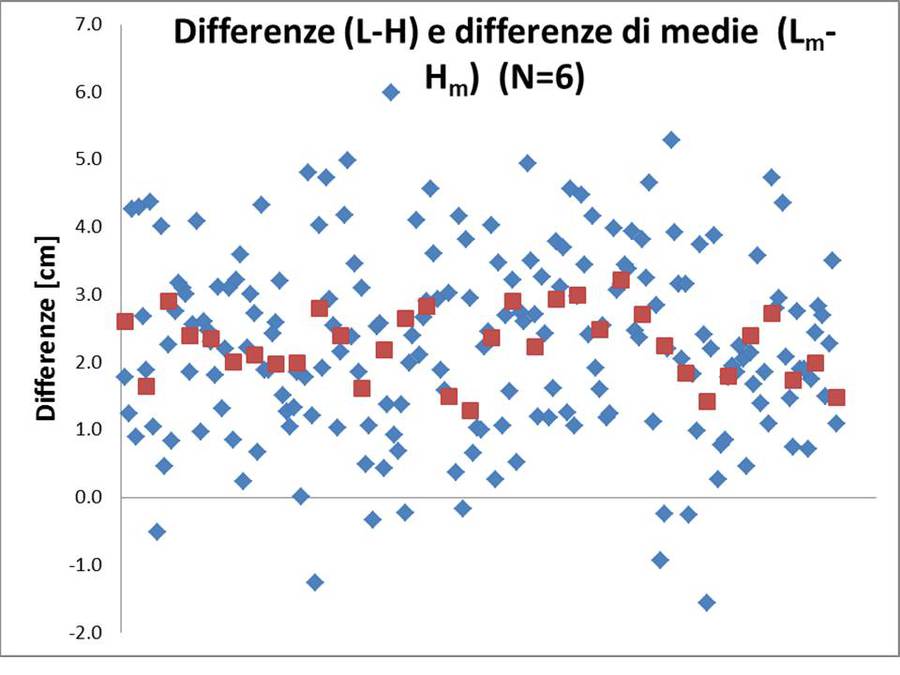
Figura 3: confronto tra una simulazione di misure di H e una simulazione di misure di L, entrambe con distribuzione gaussiana. E' evidente che l'errore massimo non permetterebbe di stabilire l'esistenza di una differenza significativa tra H e L. Considerando le medie ottenute su N=6 punti, le differenze sono evidenti.
Figura 4 Simulazione delle differenze L-H ottenute simulando 200 valori di L ed H con distribuzione gaussiana (file EXCEL allegato). In rosso le differenze di valori medi calcolati su N=6 dati. Le differenze delle medie sono più affidabili delle differenze di singoli valori che in alcuni casi sono molto vicini a zero se non addirittura negativi. La figura è riportata nel file EXCEL allegato e può essere rigenerata con un nuovo set di valori usando il tasto F9
In generale non siamo così fortunati, capita di dover valutare differenze molto meno nette. In prima approssimazione possiamo stabilire che due dati sono ragionevolmente diversi e se la differenza tra i due è maggiore di 1-2 volte l'errore sulla differenza $\sigma_D$ (somma in quadratura degli errori sui dati).
Domanda: se la differenza osservata è minore di $\sigma_D$ possiamo affermare che i due dati sono eguali? No! possiamo solo dire che non siamo in grado di osservare una eventuale differenza.
Conclusioni
La misura ripetuta dell'altezza di Alessia ci ha permesso di quantificare la dispersione dei risultati usando la deviazione standard: $\sigma_H$.
Effettuando misure ripetute è possibile ridurre l'incertezza (teorema del limite centrale) e l'errore (o incertezza) da assegnale alla media di N misure è: $$\sigma_{\bar{H}} = \frac{\sigma_H}{\sqrt{N}}$$ Questo è un errore di tipo A (GUM-chapt.4.2 chap. 4.2) ovvero ottenuto utilizzando un calcolo statistico.
La misura ripetuta dell'altezza di Alessia ci ha permesso di calibrare la nostra capacità di osservazione. Se ora dovessimo effettuare una singola misura analoga (es. l'altezza di Massimo) l'incertezza da associare alla singola misura dovrebbe essere proprio σH che avevamo visto prima. La dispersione dei risultati, infatti, è dovuta a diversi fattori quali: l'abilità dell'osservatore, la posizione del misurando, il corretto uso degli strumenti, etc... Dobbiamo supporre che il nostro valore singolo sia estratto da tutti i possibili risultati di una distribuzione la cui deviazione standard, non avendo altre informazioni è proprio σH. Questo è un errore di tipo B (GUM-chapt 4.3 chap. 4.3) ovvero un errore valutato utilizzando da tutta la nostra conoscenza a priori riguardo al fenomeno studiato.
Attenzione, se non avessimo effettuato misure in precedenza sarebbe stato lecito usare la risoluzione dello strumento come errore? Si ma... fino ad un certo punto: anche in questo caso l'intuito e l'esperienza ci dovrebbero dire che la precisione dello strumento potrebbe essere eccessiva rispetto agli errori che potremmo compiere (se ad esempio usassimo un calibro ventesimale sarebbe poco plausibile indicare un errore di 0.05 mm?).
Riguardo al numero di cifre significative da utilizzare per riportare l'incertezza, le norme ISO fanno appello appello al buon senso indicando di non usare un numero eccessivo di cifre significative (GUM-chapt 7.2.6) con un massimo due cifre significative (se ne possono usare di più in caso di problemi di arrotondamento!). In alcuni casi ho trovato l'indicazione (che trovo ragionevole) di usare una sola cifra per gli errori di tipo B (più vaghi) e due per gli errori di tipo A. In alcuni testi si suggerisce di usare una sola cifra significativa per l'errore, e usare due cifre solo se la prima è 1 (es 0.149576= 0.15, 0.352345=0.4)
Note e storia
Nota1: La [5] non è facile da dimostrare matematicamente ma il foglio EXCEL allegato permette di verificarlo empiricamente. Nel foglio 2 del file EXCEL allegato sono presentate due serie di valori che simulano la distribuzione di 200 valori di H e L (le simulazioni si aggiornano premendo F9). In tabella 5 sono riportati la media e la deviazione standard dei dati (simulati) di H ed L e della loro differenza D (tabella 5)
Tabella 5: valori medi e relativo errore di H, L e L-H ottenuti da una distribuzione simulata di 200 valori
La deviazione standard $\sigma_D = 1,48\ [cm]$ così ottenuta va confrontata con il valore calcolato in base alla [5], pari a: $$\sigma_D = \sqrt{\sigma_H^2 + \sigma_L^2} = 1,43\ [cm]$$
Nota 2: Regole per la propagazione degli errori nel caso di funzioni di due grandezze A e B.
Nel file EXCEL allegato, nel foglio simulazione errori è possibile verificare empiricamente le regole per la propagazione degli errori in alcuni casi comuni. Il foglio calcola 200 valori per due grandezze (A,B) con distribuzione gaussiana, l'utente definisce medie e deviazioni standard. Quindi il foglio:
calcola diverse funzioni di A e B: $ c \cdot A,\ A+B,\ A-B,\ A \cdot B,\ A/B,\ A^n; $
calcola media e deviazione standard per le distribuzioni ottenute;
calcola gli errori usando le regole per la propagazione degli errori di seguito riportate e le confronta con le deviazioni standard ottenute;
riporta la differenza percentuale tra la deviazione standard "sperimentale" e quella calcolata usando le regole per la propagazione degli errori. Questi risultano uguali entro qualche %
Calcolo degli errori in alcuni casi comuni di funzioni di variabili aleatorie. $$C = c \cdot A \longrightarrow \sigma_C = c \cdot \sigma_A; \hspace{12 mm} S = A + B \longrightarrow \sigma_S = \sqrt{\sigma_A^2 + \sigma_B^2}; \hspace{12 mm} D = A - B \longrightarrow \sigma_D = \sqrt{\sigma_A^2 + \sigma_B^2}; $$ $$P = A \cdot B \longrightarrow \sigma_P = P \cdot \sqrt{\frac{\sigma_A^2}{A^2} + \frac{\sigma_B^2}{B^2}}; \hspace{12 mm} R = \frac{A}{B} \longrightarrow \sigma_R = R \cdot \sqrt{\frac{\sigma_A^2}{A^2} + \frac{\sigma_B^2}{B^2}}; \hspace{12 mm} E = A^n \longrightarrow \sigma_E = nE \cdot \frac{\sigma_A}{A}$$
Nota 3: in effetti la differenza tra due medie non è proprio una distribuzione Gaussiana, ma segue una distribuzione detta t-Student che può essere approssimata ad una distribuzione di Gauss se il numero di dati è abbastanza grande (10-15 dati in totale)
Bibliografia
Per la distribuzione delle media campionarie e il teorema del limite centrale:
Distribuzione delle medie (1) (Usare il tasto Begin) l'animazione mostra l'effetto del campionamento sulla media. Si possono selezionare diverse distribuzioni per i dati di origine.
Distribuzione della media (2) L'esperimento consiste nell'estrarre un campione di dimensione n da una distribuzione data e costruire un intervallo di confidenza approssimato per la media, a un dato livello di confidenza.
Distribuzione della media (3) (In inglese) Mostra la distribuzione delle medie estratte da popolazioni con distribuzioni diverse.